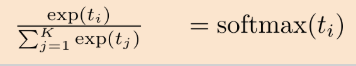https://opentutorials.org/module/3653/22995
logit, sigmoid, softmax의 관계
[logit, sigmoid, softmax의 관계]
이번에는 logit, sigmoid, softmax의 관계에 대해서 알아보겠습니다.
이것들이 서로 다 다른 개념같지만
서로 매우 밀접하게 관련이 있는데요.
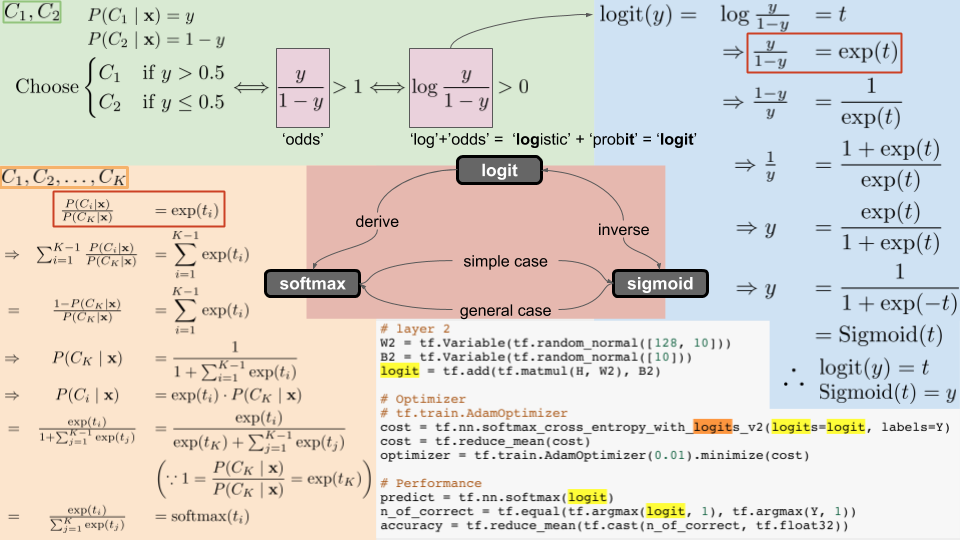
그림의 가운데 부분에서 세 개념의 관계를 화살표로 엮어놓았습니다.
결론부터 일단 말씀드리면
- logit과 sigmoid는 서로 역함수 관계이고
- 2개 클래스를 대상으로 정의하던 logit을 K개의 클래스를 대상으로 일반화하면 softmax함수가 유도(derived)됩니다.
- softmax함수에서 K를 2로 놓으면 sigmoid함수로 환원이 되고,
- 반대로 sigmoid함수를 K개의 클래스를 대상으로 일반화하면 softmax함수가 유도됩니다.
sigmoid함수는 인공신경망에서 ReLU가 등장하기 이전에 활발하게 사용되었던 activation function(활성화 함수)이고, hidden 노드 바로 뒤에 부착됩니다.
softmax함수는 인공신경망이 내놓은 K개의 클래스 구분 결과를 확률처럼 해석하도록 만들어줍니다. 보통은 output 노드 바로 뒤에 부착되고요.
코드에서 사용될때는 서로 다른 용도(sigmoid는 activation에, softmax는 classification에)로 사용되지만
수학적으로는 서로 같은 함수입니다. 다루는 클래스가 2개냐 K개냐로 차이가 있을 뿐이에요.
머신러닝을 텐서플로 예제로 처음 접하신 분은
코드 안에서 logit이라는 단어를 종종 보셨겠지만
이것이 대체 무엇이고 어떤 의미인지는 자세히 보지 않고 지나쳤을 가능성이 높습니다.
이번 기회에 아주 자세히 알아보도록 하지요.
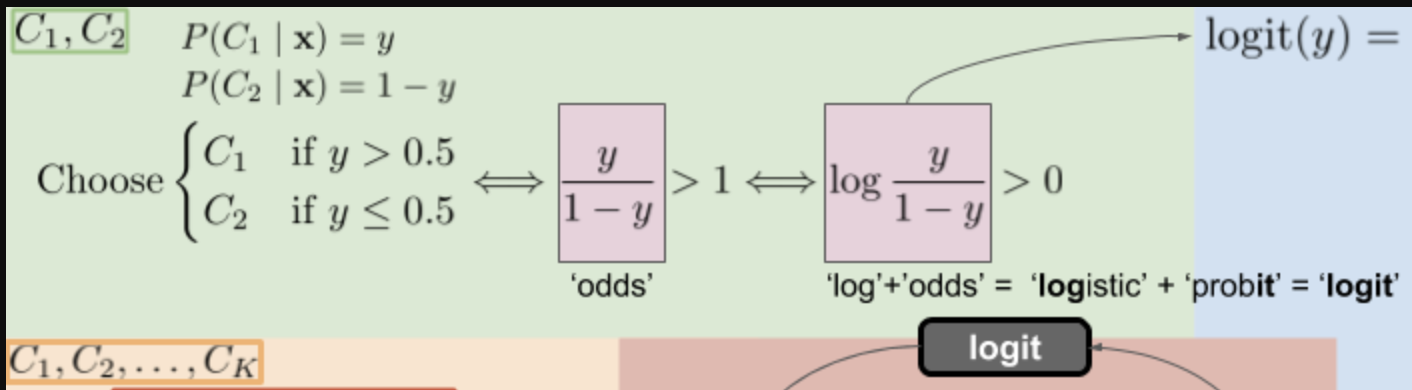
먼저 logit부터, 좌측 상단의 연두색 배경부터 읽어보겠습니다.
class1과 class2를 구분하는 이진 분류문제(binary classification)라고 하지요.
하나의 데이터 포인트 x가 주어졌을 때, 이것이 C_1으로 분류될 확률을 y라고 보면
같은 데이터가 C_2로 분류될 확률은 1-y 이지요. 모든 가능성의 총합은 1로 보는 것이 확률이니까요.
그러므로
[x가 주어졌을 때 y가 0.5보다 크다면 x를 C_1로 배정하고,
y가 0.5보다 작다면 x를 C_2로 배정하라는 결정]
을 내릴 수 있겠습니다.
이 결정을 같은 의미로 간략하게 표현한 것이 바로
odds라는 단어입니다.
odds란, 도박에서 얻을(pay off) 확률과 잃을(stake) 확률의 비율을 뜻하는 영어단어입니다.
C_1로 배정될 확률을 ‘얻는다'고 보고, C_2로 배정될 확률을 ‘잃는다'고 본다면
y가 1-y보다 커서, 그 비율이 1보다 커질 때 x를 C_1로 배정하고
y가 1-y보다 작아서, 그 비율이 1보다 작아질 때 x를 C_2로 배정하라는 뜻이죠.
이것과 또 아주 같은 의미로
log를 odd에다가 붙여서 logit이라는 것을 정의합니다.
logit은 ‘logistic’ 과 + ‘probit’ 의 합성어입니다.
probit은 확률을 재는 단위라는 뜻으로, odds의 의미(두 확률의 비율)를 그대로 가져온다고 보시면 되겠습니다.
odds는 그 값이 1보다 큰지 아닌지로 결정의 기준을 세웠다면
logit은 그 값이 0보다 큰지 아닌지로 결정의 기준을 세웁니다.
이 두 식은 완전히 같은 의미를 갖는데, x=1이면 log x는 0이기 때문입니다.
로그의 기본 성질은 고등학교 교과서를 참고해주세요.
이제 오른쪽 하늘색 배경의 수식을 보시면,
결론부터 말씀드리면, logit 함수와 sigmoid 함수는 서로 역함수 관계입니다.
로그함수의 기본 성질과 분수의 약분 통분을 다룰 수 있다면 유도할 수 있습니다.
softmax함수는 sigmoid의 일반형이라고 위에서 말씀드렸는데요,
이것을 유도하려면 약간의 산수적 테크닉이 필요합니다.
그림에서 먼저 빨간 박스로 테두리를 쳐 놓은 두 식이 같다는 것을 이해하고 시작해야 합니다.
오른쪽 식은 클래스가 2개일 때의 odds를 표현해놓은 것이고
왼쪽 식은 클래스가 K개일 때의 odds를 표현해놓은 것입니다.

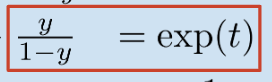
양 변을 i=1부터 K-1까지 더해주세요
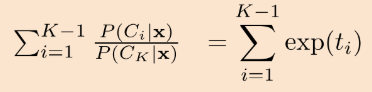
분모에 있는 C_K는 i의 영향을 받지 않으므로, 분자의 P(C_i | x)만 더해지는데요,
확률의 합은 1이기 때문에, 1부터 K-1번째 클래스의 확률을 더한 값은 1-에서 K번째 클래스의 확률을 뺀 것과 같죠.
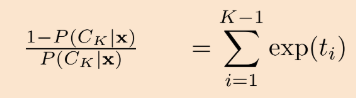
분모분자를 뒤집어서 P(C_K | x)를 기준으로 정리해줍니다.
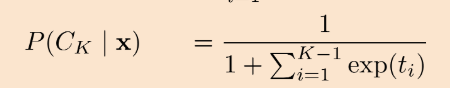
우리 맨 처음에 봤던 (빨간 박스쳐진) 식을 다르게 표현한 것이고요.
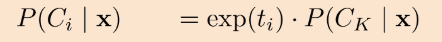
P(C_K | x)를 위 식에 대입해주고,
분모에 있는 1이 exp(t_K)로 바뀐 것을 볼 수 있는데요
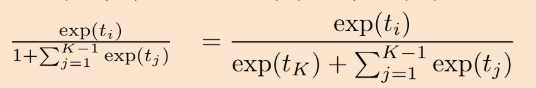
왜냐하면 아까 봤던 식에서 i 대신에 K가 들어가면 1이기 때문입니다.
점 세개를 찍어놓은 것은 '왜냐하면(because)'이라는 수학 기호입니다.

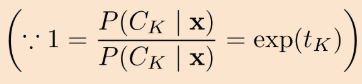
마지막으로 exp(t_K)를 시그마 기호 안으로 집어넣으면, softmax함수가 완성됩니다.