안녕하세요 드라마앤컴퍼니 빅데이터 센터의 AI Lab에서 일하고 있는 강민석입니다.
빅데이터 센터의 간략한 소개부터 하면 약 3.5억 장의 명함과 관계 데이터, 채용 정보를 활용해 비즈니스 도메인에서 더 높은 차원의 가치를 창출하기 위한 관련 연구와 관리 활동을 담당하는 조직입니다.
빅데이터 센터의 AI Lab은 Recommendation System, Ranking Model, Graph Neural Network, Natural Language Processing, Document Understanding 등 연구 영역을 넓혀가고 있으며, 기반 연구를 통해 고객의 비즈니스에서 WOW 하는 경험을 제공하고자 노력하고 있습니다.
빅데이터 센터의 AI Lab에서 주기적으로 기술 블로그에 포스팅하기로 했습니다. 많은 관심 부탁드립니다.
게시물의 내용은 아래와 같이 구성되어 있습니다.
- Document Understanding의 정의와 문제점
- Business Task (Document Image Classification, Visual Question Answering, Document Layout Analysis, Information Extraction)
- Information Extraction의 3가지 접근법과 Multi-Modal Embedding
- 마무리
Document Understanding이란?
문서 이미지를 AI 모델을 통해 문서 이미지 내용을 해석하고 유저가 필요한 정보로 가공해주는 작업

Document Understanding의 전체 흐름도 [1]
- Document Understanding의 세부적인 작업을 처리해주는 대표 기술은 네 가지가 있습니다.
- 문서를 분류(Document Classification)
- 문서를 기반으로 질문을 던졌을 때 답변(Question Answering)
- 문서에서 구성요소(Text, Title, Table)를 분석 (Document Layout Analysis)
- 문서에서 원하는 정보를 추출(Information Extraction)
- 이 글의 후반부에서 Information Extraction에 대한 접근법과 Embedding Feeding 전략에 대해 설명할 예정입니다.
- 사람이 직접 문서의 정보를 추출하는 것은 정확도가 낮고 재사용성이 낮아 시간이 오래 걸리고 노동 집약적입니다. 이를 해결하고자 Document Understanding에 대해 많은 연구가 진행되고 있습니다.
- Document Understanding은 실제 저희 주변에서 자주 사용될 수 있습니다.
- 리멤버의 명함 입력, 금융 어플에서의 주민등록증 정보 자동 입력, 송장 및 계약서 자동입력 등이 있습니다.
- 2025년까지 150조 기가바이트(150 제타 바이트) 이상의 비정형 데이터를 분석해야 할 것으로 추정된다고 합니다.[2]
- Document Understanding은 현재 Microsoft, Google, Amazon과 같은 다국적 기업 뿐만 아니라 다양한 기업 및 학계에서 관련 논문이 쏟아져 나온다고 해도 과언이 아닐 정도로 많은 연구가 진행 되고 있습니다.
Document Understanding의 문제점
- 사진 촬영 문제와 텍스트의 속성에 따라 성능은 계속 변화합니다.
- 너무 밝거나 어두운 이미지, 움직이는 피사체, 블러현상 들은 글자를 읽기 어렵게 만듭니다.
- 글자의 다양한 폰트, 크기, 색상뿐만 아니라 구겨져 있는 종이에 쓰여 있는 글자, 복잡한 배열들은 글 전체의 해석이 어렵게 합니다.
- 관련 연구 – 이미지의 Denoising, Super Resolution, 합성 및 증강 기술에 관한 연구
- 학습 데이터의 부족 및 수집의 어려움
- 품질이 높은 학습 데이터를 만들어 내는데 큰 비용이 필요합니다.
- 관련 연구 – Multi-Task Learning, Active-Learning, Synthetic Data 등 연구
- 문서 내용의 문맥을 이해하기 위한 거대한 Language Model을 만들고 수정하는 데 어려움이 있습니다.
- 새롭게 Language Model을 학습하는 데 필요한 자원(인프라, 시간, 비용)이 많이 필요합니다.
- 복잡하고 긴 문서의 정보는 한 번에 입력받기 어려워 쪼개서 입력할 때 결과 값을 예측하기 어렵습니다.
- 관련 연구 – 페이지를 부분적으로 나누어 상관관계를 포함한 모델, Lightweight 모델 설계에 관한 연구
Business Task (Downstream Task)
문서 이미지를 OCR을 통해 디지털화된 텍스트 정보로 변환하고 디지털 텍스트 정보를 활용해 비즈니스에 필요한 문제를 해결하는 작업을 뜻합니다. 일반적으로 사전 학습된 Language 모델을 Business Task에 맞게 Downstream Task를 추가하여 Fine-Tuning 하여 문제를 해결합니다.
대표적으로 Document Image Classification, Visual Question Answering, Information Extraction, Document Layout Analysis가 있습니다.
1. Document Image Classification
문서 이미지를 과학 논문, 이력서, 청구서, 영수증 및 기타 여러 범주로 자동 분류하는 작업입니다.

2. Visual Question Answering
문서 이미지에서 획득한 텍스트 정보, 시각 정보 및 레이아웃 정보를 분석하여 질문에 대한 답을 출력하는 작업입니다.
Document Visual Question Answering [3]
3. Document Layout Analysis
문서 레이아웃에서 텍스트 및 시각적 정보를 활용하여 표/그림/차트 정보 및 위치 관계를 찾아 주는 작업입니다.
Document Layout Analysis [4]
4. Information Extraction
문서에 있는 2차원 공간에 배열된 비정형 정보에서 필요로 하는 정보만을 추출하는 기술을 나타냅니다.

Information Extraction [5]
Information Extraction의 3가지 접근법
3가지 접근법과 LayoutLM 시리즈, Docformer, PICK, ViBERTgrid 논문을 소개합니다.
1. Sequence-based approaches
텍스트 정보, 시각 정보 및 레이아웃 정보 시퀀스로 직렬 화한 다음 NLP의 기존 시퀀스 태깅 모델을 사용하여 원하는 정보와 클래스값을 추출합니다.
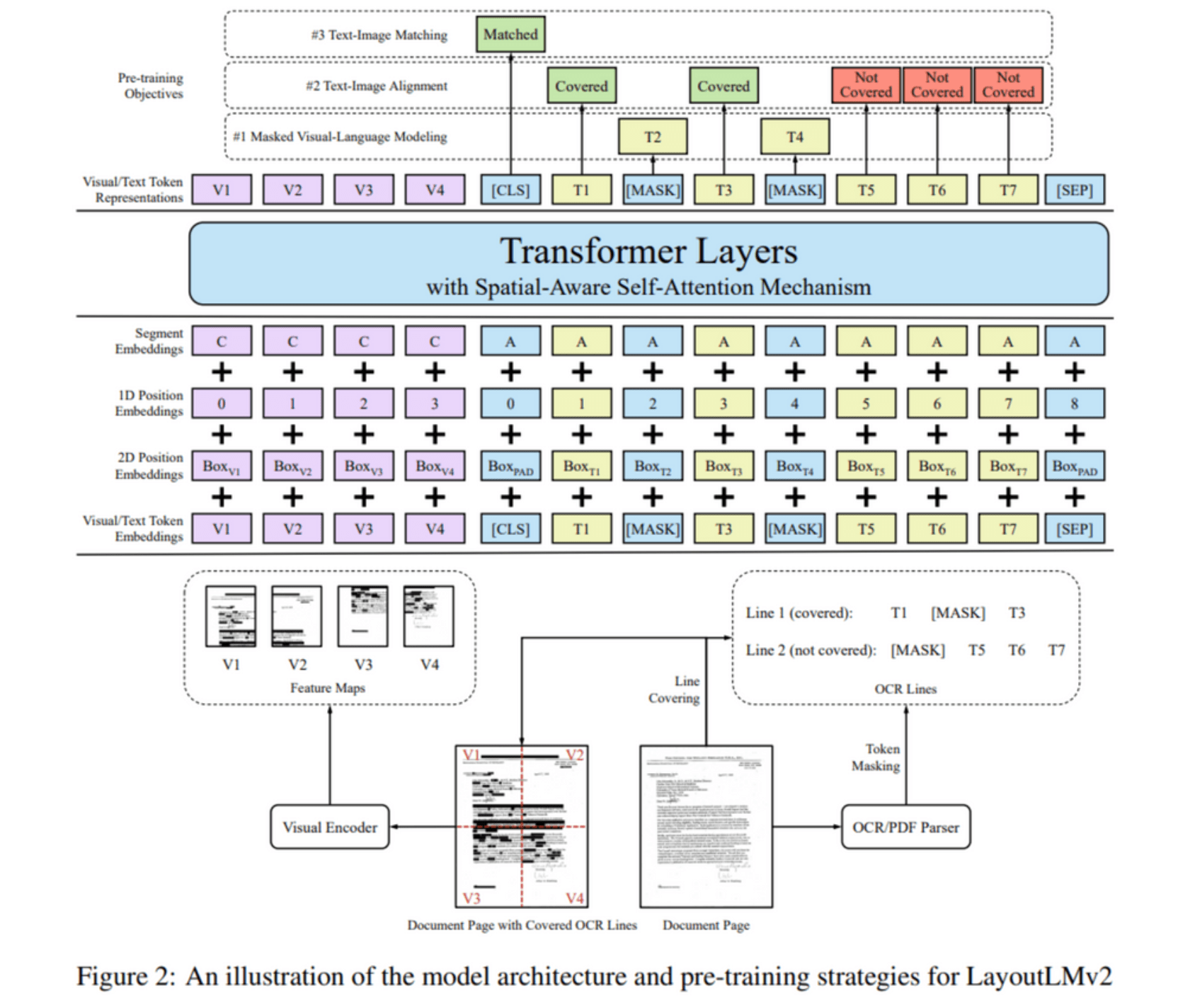
- Layoutlmv2 [6]
- Multi-Modal 정보를 이용한 사전 학습 전략을 제안했다.
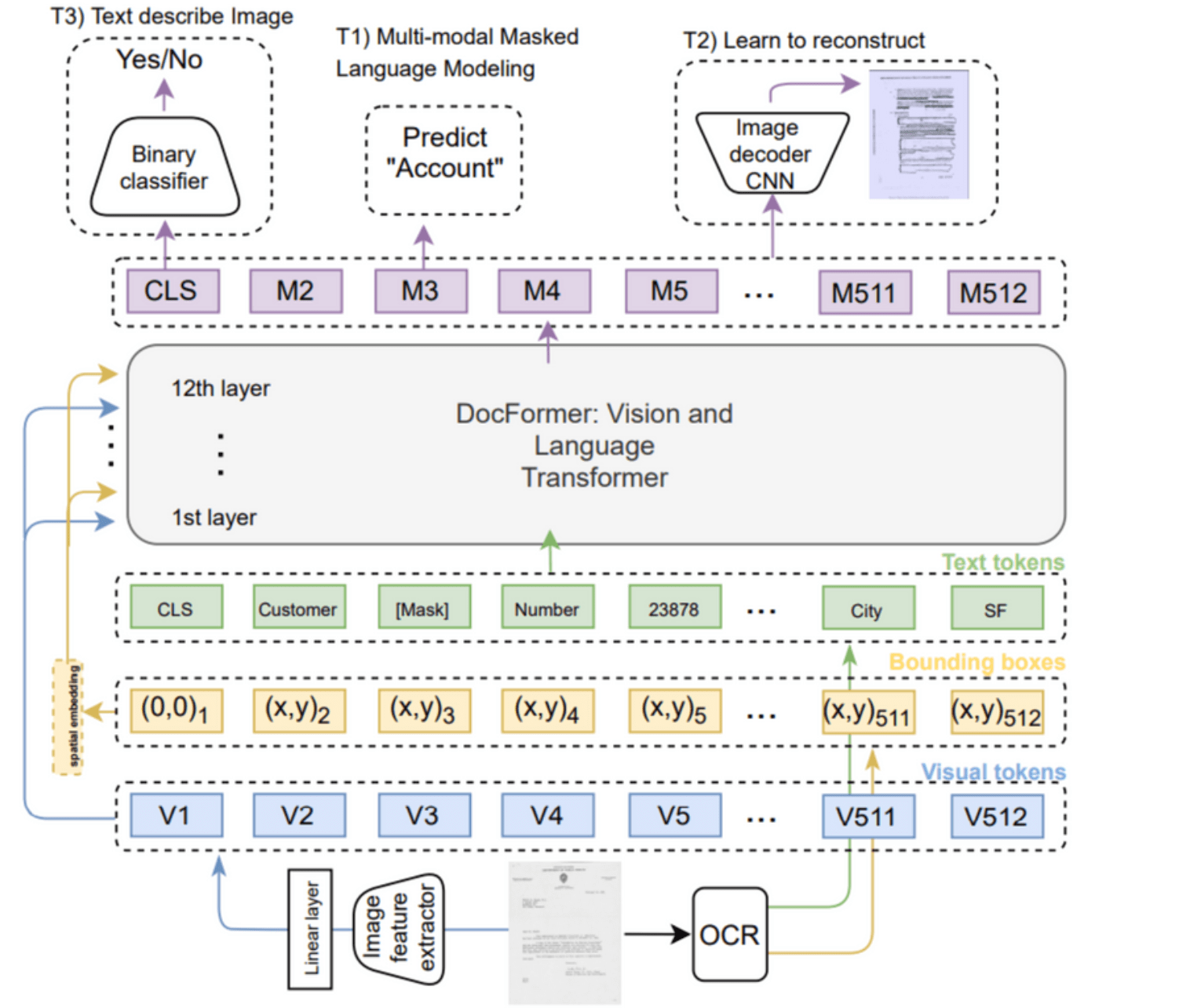
- Docformer [7]
- 텍스트, 시각 및 레이아웃 정보의 상관관계를 학습시키기 위한 Cross-Modality Feature Correlation을 통한 Embedding Feeding 전략을 제안했다.
- Multi-Modal Self-Attention Layer 구조 설계를 제안했다.
2. Graph-based approaches
문서 각 페이지 정보를 그래프로 모델링하며, 텍스트 정보는 노드로 표시되고 표현되는 정보에 시각적, 텍스트 및 위치 기능을 결합하는 방법입니다.
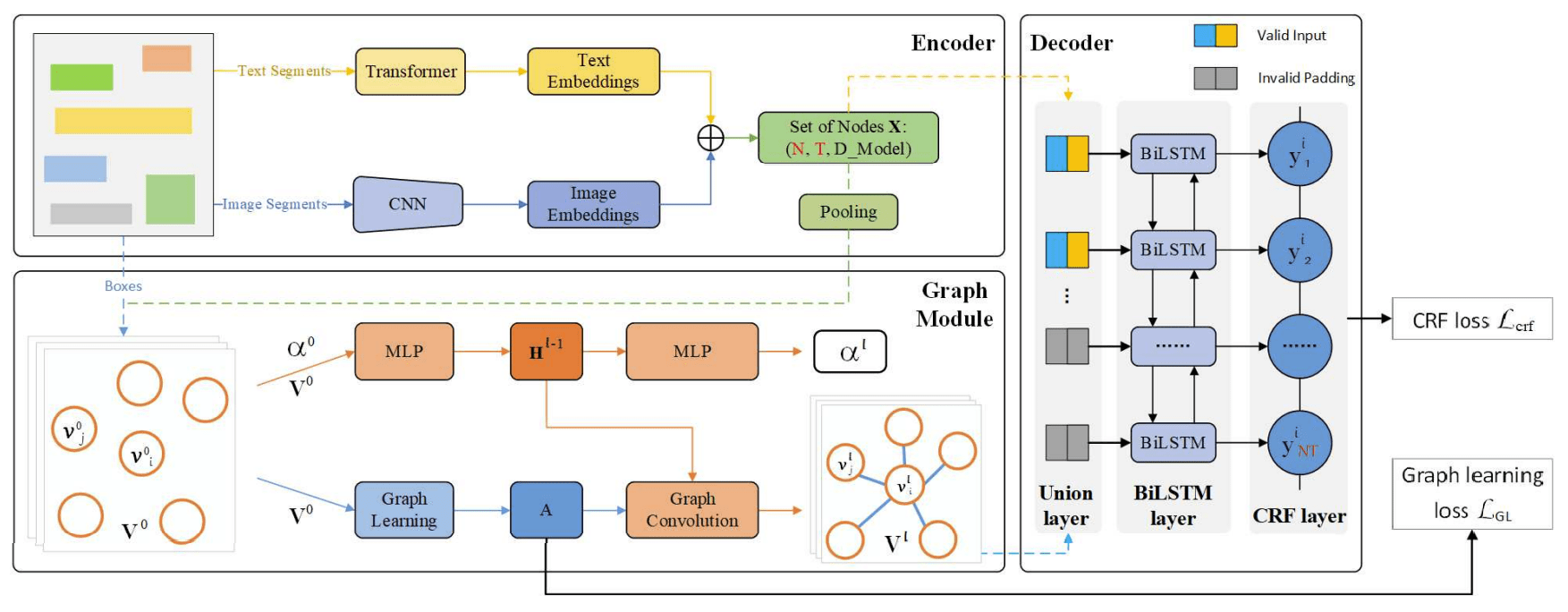
- PICK [8]
- Graph를 이용하여 텍스트 정보의 시각적, 위치 정보 결합한 모델을 제안했다.
3. Grid-based approaches
텍스트 정보의 토큰 임베딩을 2D 그리드로 표현한 다음 Instance Segmentation 모델에 Feature와 결합하여 2D 그리드에서 원하는 정보와 클래스값을 찾는 방법입니다.
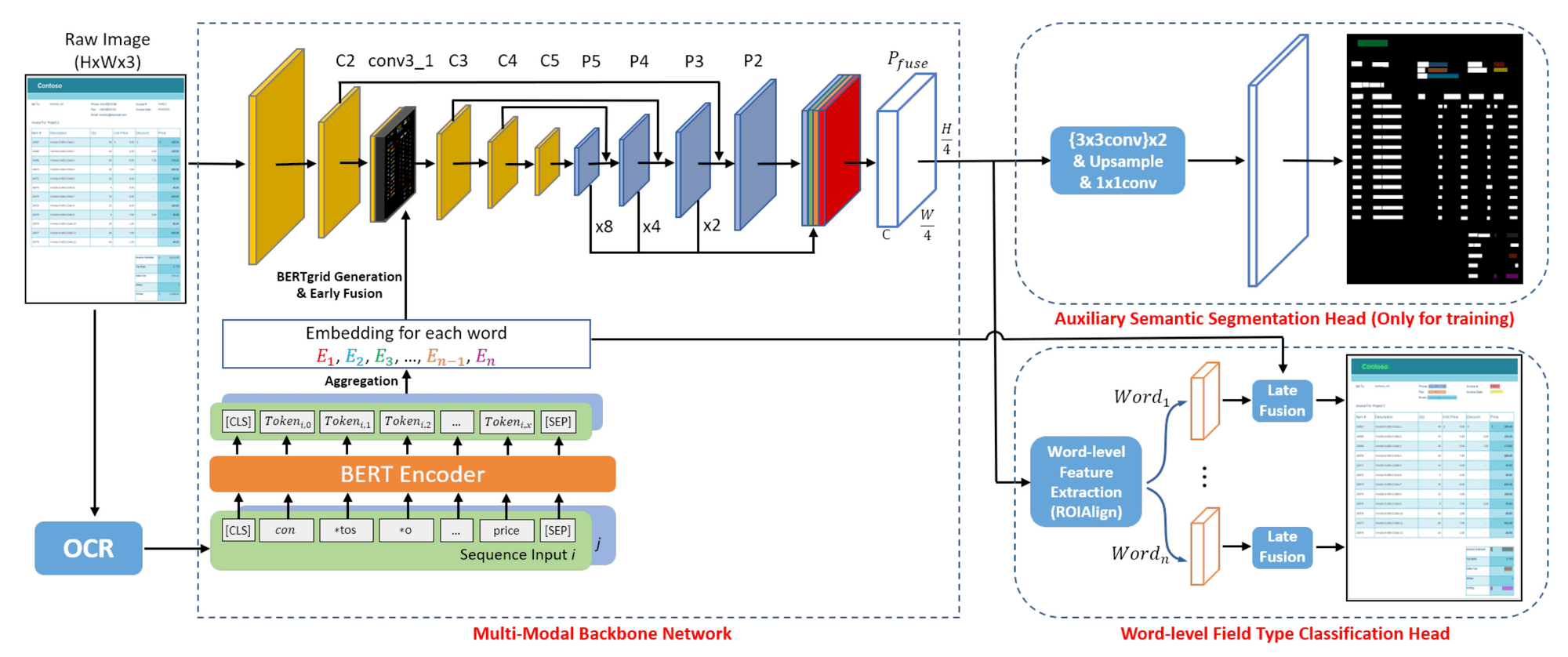
- ViBERTgrid [9]
- 기존 방대한 Dataset으로 사전 학습된 Model에 의존 하지 않고 시각적 정보에 좀 더 초점을 맞춘 모델
Multi-Modal Embedding
시각적으로 정보가 풍부한 문서에는 주로 텍스트 정보, 시각적 정보 및 레이아웃 정보를 포함하고 있습니다. 이를 각각 임베딩 화 하여 모델의 입력으로 활용하는 기술입니다. 세 가지 임베딩(Text, Visual, Spatial)을 소개하고 위에 소개한 논문을 통해 비교를 하겠습니다.
1. Text Embedding
일반적으로 단어 단위 텍스트를 토큰 화하고 1차원 위치 임베딩 및 세그먼트 임베딩을 추가하여 최종 텍스트 임베딩을 얻습니다.
- LayoutLM 시리즈, Docformer, PICK의 경우 : 단어 단위 Tokenizer를 통해서 토큰화된 값
- ViBERTgrid의 경우 : BERT Encoder를 활용해 추출된 Word 임베딩
2. Visual Embedding
일반적으로 Visual Backbone을 이용하여 fature map을 추출한 다음 Pooling 및 Flatten을 거쳐 나온 벡터를 고정 차원 벡터를 얻기 위해 Linear Projection을 거칩니다.
- LayoutLM 시리즈, Docformer, PICK의 경우 : Visual Backbone(Resnet-FPN, Resnet50)를 사용해 피처 추출 후 Flatten 및 Linear 작업으로 Shape 변형된 값
- ViBERTgrid의 경우 : Resnet 모델 2번째 레이어 결과 값에 Text 임베딩을 합쳐서 최종 P_fuse Feature 맵 계산하여 Segmentation과 Classification을 진행하여 암묵적으로 학습
3. Spatial(Position) Embedding
단어의 이미지상의 위치 좌표와 텍스트 상자의 너비와 높이, 좌표간의 상관관계를 벡터화하여 Spatial 임베딩을 얻습니다.
- LayoutLM 시리즈 : OCR 박스 값의 좌표와 상대적인 거리를 추출하여 Text 임베딩과 Visual 임베딩에 각각 결합하여 Transformer로 입력
- Docformer의 경우 : OCR 박스 값의 좌표와 상대적인 거리를 추출하여 Multi-Modal Self-Attention Layer의 각 모든 레이어에 추가로 결합
- ViBERTgrid의 경우 : 전체 모델의 흐름 안에서 Text과 Visual, Spatial 표현이 암묵적으로 학습된다고 판단
- PICK의 경우 : OCR 박스 값의 좌표와 상대적인 크기를 Graph 모델 구조로 활용
마무리 하며
Document Understanding에 대한 소개, Business Task, Information Extraction의 3가지 접근법과 Multi-Modal Embedding을 소개하였습니다. Document Understanding은 현재에도 많은 연구가 진행되는 분야이며 실제 다양한 분야에서 활용도가 높은 연구중 하나 입니다. 특히, 드라마앤컴퍼니의 명함인식 서비스와 같이 특정 도메인에 최적화하게 된다면 기존 서비스에서 고객에게 더 WOW 할 수 있는 경험를 제공해줄 수 있는 연구 분야라고 생각됩니다.
본 글에서는 Document Understanding에 대해 전반적으로 이해를 돕기 위해 사전 학습 방법 및 Multi-Task 학습 전략등 복잡한 수식은 제외하고 설명하였습니다. 자세한 내용은 아래의 레퍼런스 논문을 통해 확인하시거나 댓글을 통해 문의 부탁드립니다. 처음 작성한 기술 블로그이다 보니 부족한 부분이 많은 것 같습니다. 다음 작성하는 기술 블로그는 좀 더 알차게 구성하도록 노력해보겠습니다.
부족하지만, 읽어 주셔서 감사합니다.
Reference
[1] Cui, Lei, et al. “Document AI: Benchmarks, Models and Applications.” arXiv preprint arXiv:2111.08609 (2021).
[2] https://en.wikipedia.org/wiki/Document_layout_analysis
[3] Mathew, Minesh, et al. “InfographicVQA.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022.APA
[4] Zhong, Xu, Jianbin Tang, and Antonio Jimeno Yepes. “Publaynet: largest dataset ever for document layout analysis.” 2019 International Conference on Document Analysis and Recognition (ICDAR) . IEEE, 2019.
[5] What is Information Extraction? – A Detailed Guide [by Vihar Kurama, https://nanonets.com/blog/information-extraction/]
[6] Xu, Yang, et al. “Layoutlmv2: Multi-modal pre-training for visually-rich document understanding.” arXiv preprint arXiv:2012.14740 (2020).
[7] Appalaraju, Srikar, et al. “Docformer: End-to-end transformer for document understanding.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.APA
[8] Yu, Wenwen, et al. “PICK: processing key information extraction from documents using improved graph learning-convolutional networks.” 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021.APA
[9] Lin, Weihong, et al. “ViBERTgrid: A Jointly Trained Multi-Modal 2D Document Representation for Key Information Extraction from Documents.” International Conference on Document Analysis and Recognition. Springer, Cham, 2021.APA

